|
已经陪伴了我们五年多的NetBurs微架构即将完成它的历史使命,英特尔最新推出的Core微架构产品将会在2006年第三季度上市。在本期文章中,CHIP将带领您进入微处理器的世界,领略英特尔的最新技术给CPU的性能带来的革命性变化。
可以说2003年9月23日是CPU发展史上值得纪念的日子之一,这一天,AMD公司发布了Athlon
64处理器,它凭借强大的性能向英特尔Pentium 4发起了冲击。此后,英特尔很快发布了Prescott核心的产品,Prescott
Pentium
4拥有最高达到3.8GHz的运行频率和1MB/2MB的大二级缓存,但它带来的性能提升并不令人满意,同时发热量却几乎令人难以忍受,而AMD则依靠Athlon
64不断在零售和品牌机市场上取得突破。虽然英特尔65纳米工艺的Cedarmill和Persler核心处理器降低了功耗和成本,但它们仍然采用NetBurst微架构,难以在与更新的AMD处理器的对抗中取得优势。与桌面市场上节节败退的态势相反,在笔记本电脑市场上,英特尔采用全新Mobile微架构(这一微架构没有官方的名称,参照Core微架构白皮书中的名称命名为Mobile)的移动处理器Pentium
M/Core Duo却在不断高歌猛进,大有一统天下之势,它出色的性能甚至可以和AMD Athlon FX系列媲美,功率则远比Pentium
4小得多。下一代处理器微架构能否同时拥有Mobile和NetBurst微架构的优点呢?2006年3月,英特尔正式发布的Core微架构没有让大家失望。
Core微架构:从频率到效率
是什么最终决定一款CPU是不是成功的产品?英特尔和AMD近几年的竞争给出的答案是效能,也就是能源效率。因此在新一代的Core微架构的设计上,英特尔更加强调了节能、高效的设计理念。
决定CPU性能的因素
CPU的性能不完全取决于运行频率(F),也不完全取决于每个时钟周期内处理的指令数(IPC),而是由这两者共同决定,换言之,性能(P)是F和IPC两者的乘积。要提高CPU的性能,可以通过提高CPU的运行频率与提高CPU每个时钟周期处理的指令数目两个手段来达到。前者的实例就是自4004出现以来,CPU频率的不断攀升;而后者最著名的例子就是MMX、SSE/SSE2/SSE3等扩展指令集,以及英特尔在Mobile微架构中引入的微操作融合(Micro-op
Fusion)。
CPU的效能
在定义CPU的效能时,科学家们提出了每指令耗能(Energy per Instruction,EPI)和每瓦效能的概念,EPI值越大,处理器的能源效率就越差,后者则刚好相反。一颗微处理器的EPI决定因素有三个方面:设计(包括微架构、逻辑、电路、布线等等)、加工工艺和供电电压。来自一份英特尔研究报告中的数据给出了一些CPU的EPI值对比。
从这份表中可以看出(见表1),Pentium 4处理器的等效EPI值最大,也就是能源效率最差,而i486则具有最好的等效能源效率(假设i486也是以65纳米工艺生产并且工作于1.33伏电压下)。这是因为前者具有深的流水线、大的乱序执行结构和误推测,这些都导致动态
电容值更高,处理每个指令的耗能值也更大。而Mobile架构的产品更加出色,Yonah以相当于i486的EPI值,达到了i486
7.7倍的性能。无疑,这样的产品才代表着未来的发展方向,Core微架构的设计就延续了这样的理念――用尽可能少的能量,获得尽可能高的性能。
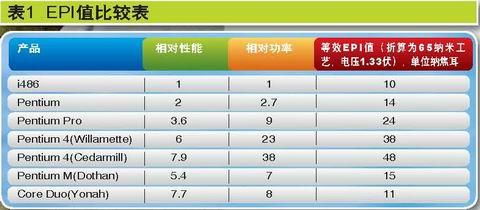
EPI值比较表
Core微架构的特点
Core微架构可以说是英特尔自Pentium Pro以来最富革命性的架构之一,它担负起了同时接替NetBurst和Mobile微架构的重任。Core微架构的主要特点有以下几个方面:
14级指令执行流水线设计
早期的Williamette和Northwood核心Pentium 4 CPU都采用了20级指令执行流水线的设计,比Pentium Ⅲ和Athlon的流水线增长了1倍左右;而Prescott核心则采用了创纪录的31级流水线。长流水线的使用有利于提高CPU的运行频率,但一旦产生分支预测失败,或者缓冲区未命中,则会产生较大的延迟。不幸的是,目前的半导体工艺能够达到的CPU运行频率还不足以抵消这一负面影响;此外,运行频率增加,耗电量也会相应加大。因此在新一代的Core微架构中,英特尔采用了折中的14级指令执行流水线,这一数目高于Banias的12级,低于K8的17级,目前看来,这是一种兼顾性能和耗电量的不错的解决方案。Core微架构没有对超线程技术提供支持,这可能是由于Core微架构的流水线长度比较短,加上它对指令的处理更加高效,因此超线程技术不会带来更多性能提升的缘故。
4组指令编码器和3个算术逻辑单元
Core架构内建了4组指令编码器,包括三组简单编码器和一组复杂编码器,在一个时钟周期内,可以同时编码4个x86指令,其中复杂编码器可以处理由4个微指令所组成的复杂x86指令。在此前的十余年间,除了AMD
K5外,在桌面x86体系中尚未出现过4组指令编码器的设计。此外,Core微架构的每个核心都拥有3个算术逻辑单元(ALU),而NetBurst微架构只拥有2个ALU,Pentium
Ⅲ则仅有1个,这些设计使得Core架构拥有更加强大的处理能力。
共享式二级缓存
Core微架构与英特尔前几代桌面双核产品的另一个重大区别是前者使用了共享式二级缓存,其中Conroe的共享式二级缓存达到了4MB。这一设计带来的好处是多方面的:首先是拥有更高的缓存容量利用率,其次是两个核心的一级缓存可以直接通过二级缓存,而不是前端总线交换数据,加快了处理速度,还可以减少缓存数据一致性对性能造成的不利影响。
Core微架构的身世
根据英特尔的官方说法,Core微架构的设计综合了Moblie和Netburst两种微架构的优点。此前一些CPU-Z测试结果表明,Conroe与Tualatin、Banias/Dothan/Yonah同属于家族(Family)6,而NetBurst架构的产品则属于家族F。因此可以推断,Core微架构更多具有Pentium
Ⅲ/Pentium M家族的血统。
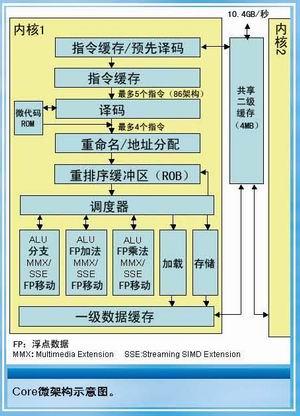
Core微架构示意图
Core微架构的创新
与前一代的NetBurst和Mobile微架构相比,Core微架构拥有更多的创新功能,它们是宽动态执行、智能功率能力、先进智能缓存、智能内存访问和高级数字媒体增强。这五大功能将成为Core微架构产品的利器,它们确保了Core微架构在拥有强悍的性能的同时,还能达到很高的能源效率。
宽动态执行
宽动态执行(Wide Dynamic Execution,WDE)的性能
动态执行是英特尔最早在P6微架构上应用的,它是数据流分析、推测执行、乱序执行和超标量体系的结合,在NetBurst微架构中,英特尔又引入了先进动态执行引擎,它是一个非常深的乱序推测执行引擎,还拥有增强的分支预测执行算法以减少分支误预测。在Core微架构中,动态执行能力则被进一步加强为宽动态执行,Core微架构的每个核心能够一次同时拾取、分派、执行、返回4个完全指令(NetBurst和Mobile微架构只能一次处理3个完全指令)。此外,宽动态执行还拥有更强的分支预测能力,更深的指令缓冲和一些减少执行时间的特性,如微操作融合和宏融合等。
宏融合(Macrofusion)
宏融合可谓Core微架构的一大特色,它可以减少执行指令所需的时间。在过去的处理器中,每个输入的指令的解码和执行都是分开进行的,宏融合则可以将普通指令对(如比较+条件跳跃)在解码时合并成单一的内部指令(微操作,Micro-op),这个合并的指令将被作为一个微操作进行处理,从而有效减少指令处理的时间。在Core微架构中,每个核心都有一个增强的ALU更便于宏融合的处理。
微操作融合(Micro-op Fusion)
微操作融合在Mobile架构中就已经出现,Core架构则继承了这一技术。在现代主流x86
处理器中,x86程序指令(宏操作)在被发送到处理器的管线中进行处理之前,会被分成若干个微操作,微操作融合可以将来自同一个宏操作的微操作合并,从而减少需要处理的微操作数目。在Core微架构中,可以内部合并的微操作的数目也比Mobile微架构有了增加。
智能功率能力
按需启动能力
Prescott核心一个被广泛批评的缺点就是功率过大,而Core微架构则引入了Mobile核心的节能技术,在功耗控制上做得非常出色。在CPU内部,英特尔设置了数码热量传感器,能够实时侦测处理器热量,并通过专门的电路控制动态电压调节、运行模式调节和风扇运行调节。此外,Core微架构处理器内的各功能单元也并非总处于全部启动状态,而是根据预测机制,仅启动需要启动的单元。这样,Merom的晶体管可以比Yonah进入更“深”的休眠,这也是它虽然二级缓存比Yonah大一倍,但功率却和Yonah持平的原因之一。此外,在不同运行模式下,单个核心也可能会被关闭以节约电池电量。
分割式总线(Split Busses)
Core微架构的另一个节能措施是采用了分割式总线的设计。在Core微架构处理器中,仅有遇到特殊的情况,比如需要长数据宽度的时候,才会启用全部的总线宽度,而在不需要应用全部总线宽度时,则启用一半总线宽度,以节约电力。
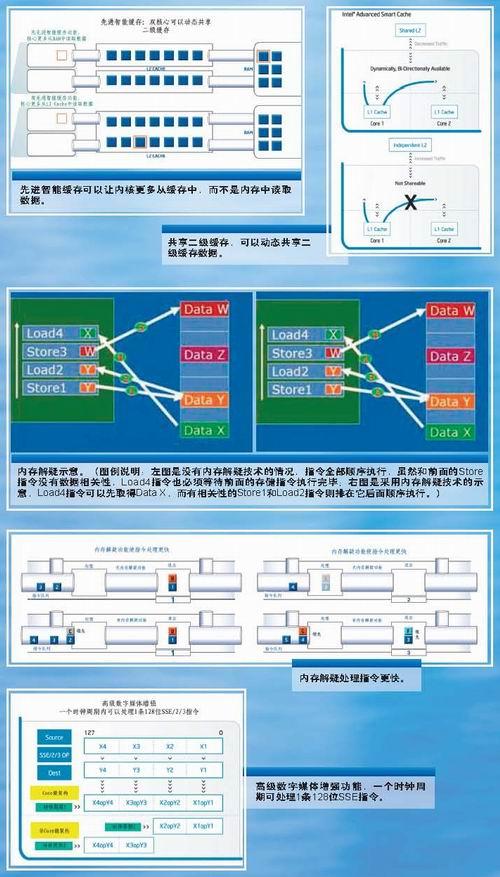
先进智能缓存
先进智能缓存(Advanced Smart Cache)可以使多内核CPU能够更好地共享缓存的数据。Core微架构的CPU和Yonah一样,都拥有共享式二级缓存,这也是这种设计第一次在英特尔的桌面产品上出现。此前的双内核/双核心产品都是每个核心拥有独立的二级缓存。先进智能缓存允许双内核动态共享二级缓存,如一个内核需求较少的缓存时,另一个内核就可以访问更多的缓存,提高了二级缓存的利用效率。此外,两个内核拥有的一级缓存也可以通过二级缓存交换数据。
智能内存访问
智能内存访问(Smart Memory Access)的功能
由于AMD K8内置了内存控制器,加上强大的HyperTransport总线,因此它的内存访问比Pentium
4更加高效。而在Core微架构中,英特尔仍然没有整合内存控制器,而是采用了智能内存访问技术来提高效率。智能内存访问技术的功能就是尽可能地减少访问内存的延迟,提高CPU和内存之间数据交换的效率。
内存解疑
内存解疑(Memory
Disambiguation)技术是智能内存访问中包含的一个重要的新技术。它使核心能够智能化地在前面的存储指令执行之前预测并载入即将处理的指令的数据,从而提高了乱序处理的效率。实际上,它是一种内存数据相关性的预测技术。通常在乱序微处理器重排指令的时候,不会将载入指令(Load)排在存储指令(Store)之前,因为它并不能得知它们的数据地址是否相关,如果它们使用相同地址,先处理载入指令就可能发生一致性错误。但实际上,很多载入指令是与前面的存储指令无关的,可以被预先载入。内存解疑技术就是这样一种智能的算法,它能够智能化判断后面的载入指令是否与前面的存储指令相关,如果没有相关性,则这个载入指令可以被提前执行,从而缩短等待时间,提高效率。在极少的情况下,预测的载入会发生错误,内存解疑技术会智能地检测反馈,并载入正确的数据。
先进预取器(Advanced Prefetchers)
先进预取器是智能内存访问技术的另一个重要技术。先进预取器可以在内容被请求之前,预先将内容从内存中载入到缓存中,使内容尽可能从缓存中而不是从内存中获取,提高了执行的效率。在Core微架构中,每个内核的一级缓存都拥有两个预取器,共享的二级缓存也拥有两个预取器,先进预取器和内存解疑技术的结合保证了Core微架构拥有最大化的系统总线带宽,缩短了内存延迟,从而提高性能。
高级数字媒体增强
高级数字媒体增强(Advanced Digital Media
Boost)功能赋予Core微架构完整的128位SSE执行单元。此前的大部分处理器仅仅提供了64位SSE指令处理单元,要执行一条完整的128位SSE指令需要2个时钟周期,而Core微架构的处理器可以在一个时钟周期内处理128位乘法、128位加法、128位数据载入和128位存储,执行一条完整的128位SSE/SSE2/SSE3指令只需要一个时钟周期。高级数字媒体增强功能可以使Core微架构处理器在处理图像、视频和音频时如虎添翼。
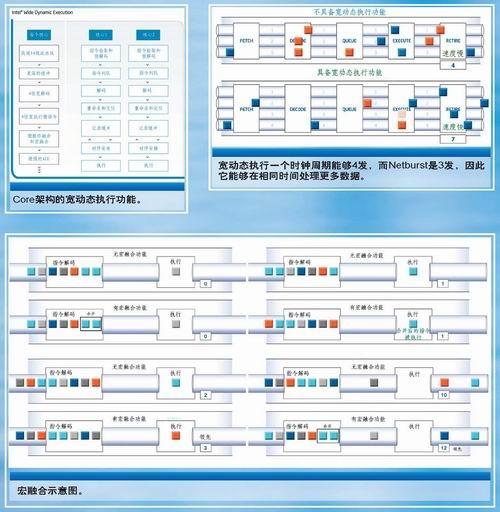
宏融合示意图
第一代Core微架构处理器
第一代Core微架构处理器将采用65纳米工艺生产,它们包括将在2006年推出,用于桌面电脑的CPU Conroe,用于笔记本电脑市场的Merom和用于服务器处理器市场的Woodcrest以及将在2007年推出的一些产品。据英特尔的资料显示,Conroe的性能将比前一代产品Pentium
D 950高大约40%,同时耗电量也下降大约40%;Merom将在与Core Duo
T2600耗电量持平的基础上,性能提高20%;WoodCrest的性能将比Xeon
2.8GHz高80%,耗电量减少35%,这无疑是一个了不起的成就。
Conroe处理器
用于桌面的Conroe处理器将在今年第三季度发售,分为2MB二级缓存的E6300和E6400,运行频率分别为1.86GHz和2.13GHz,它们的售价预计为209和244美金;主攻中高端市场的是拥有4MB二级缓存的E6600和E6700,运行频率分别为2.4GHz和2.67GHz,售价则达到了316和530美金。到今年第四季度,运行频率达到2.93GHz的E6800将出现在市场上,它们的前端总线频率都是1066MHz。2007年第一季度,Conroe
EE版可能也将出现,它的运行频率将高达3.33GHz,采用1333MHz前端总线,功率为95瓦。在此前的媒体测试中,E6700以平均20%的性能优势击败了AMD
Athlon FX60,这无疑使广大用户对Conroe充满了期待。
Merom处理器
Merom处理器将比Conroe稍晚上市,它是英特尔支持EM64T的第一款移动处理器。Merom处理器将分为T5000和T7000两个系列,最高功率为35瓦,型号包括T5500
(1.66GHz、2MB L2)、T5600(1.83GHz、2MB L2)、T7200(2GHz、4MB
L2)、T7400(2.16GHz、4MB L2)及T7600(2.33GHz、4MB
L2),前端总线频率667MHz,每千颗售价分别为209、241、294、423及637美元。除此之外,2007年1月还将发布Merom超低电压版本,型号为U7500,运行频率为1.06GHz,内建2MB二级缓存,前端总线频率为533MHz。这些CPU也将成为2007年第一季度发布的第四代迅驰平台Santa
Rosa的一部分。
Woodcrest处理器
Woodcrest处理器将在今年第三季度或第二季度末出现在市场上,六款标准版分别是Xeon DP
5160(3.00GHz)、5150(2.66GHz)、5140(2.33GHz)、5130(2.00GHz)、5120(1.86GHz)和5110(1.60GHz),最高功率不超过80瓦。此外,英特尔还将推出编号为5148的低电压版Woodcrest,它运行频率为2.33GHz,功率仅有40瓦。它们的售价分别将是850、700、450、320、255、210和520美元,对AMD
Optron 2XX处理器构成很大的威胁。

Conroe
英特尔的45纳米工艺
英特尔依然保持着每两年更新一代制造工艺的惊人速度。45纳米工艺已经成熟,将在2007年年中投入CPU生产,按照近年来的规律,我们预测采用45纳米和更新的工艺才能真正发挥Core微架构的威力。
45纳米工艺的进步
2006年1月,英特尔宣布了使用45纳米工艺的SRAM芯片生产成功,他们展示的这款SRAM芯片采用193纳米干法光刻技术,存储容量高达153Mbit,晶体管数目达到10亿个,芯片面积119平方毫米。由6个晶体管组成的SRAM存储单元的面积为0.346平方微米,大约相当于65纳米工艺的存储单元面积的一半,这也意味着采用45纳米工艺的产品单晶体管成本将更加低廉。
在性能上,45纳米工艺的晶体管也获得了很大进步。与65纳米工艺的产品相比,它的漏电量减少为五分之一,晶体管开关切换速度提高20%,工作电流将减少30%,因此它将具有更好的节能效果和更高的性能。
未解之谜
在以往的路线图中,P1266(45纳米)工艺将采用金属栅极和高K电介质,我们也曾经乐观地预测45纳米工艺中将引入这两项新技术(详见2005年第6期前沿技术文章《65nm与双核心
下一代CPU的发展前瞻》),不过英特尔在目前还没有公布相关的信息。从最近的消息看来,英特尔的成熟技术有着异乎寻常的生命力:英特尔方面曾经表示,将不会考虑在未来的产品中引入SOI工艺,应变硅技术将在45纳米和32纳米工艺中继续应用;此外193纳米光刻技术的进展也使得它能够用到2010年,此后才可能引入EUV技术;惟一的例外是原计划在2012年应用的450毫米晶圆将可能在2008年后就开始采用以大规模降低成本。因此我们推测金属栅极和高K电介质很可能到32纳米工艺时才能投入使用。
45纳米CPU产品
2007年下半年,英特尔的CPU将全面转向45纳米工艺生产,届时第二代Core微架构的CPU也将与我们见面,用于笔记本电脑市场的Penryn就是其中的代表。它的运行频率可能将比Merom稍高,拥有3MB或6MB的共享二级缓存。而主流桌面产品则包括Ridgefield和Wolfdale,它们同样也有6MB/3MB共享二级缓存,运行频率很可能超越3GHz。此外,四内核,单核心封装的Bloomfield和八内核,多核心封装的Yorkfield和Hapertown也将在2008年出现,后两者将拥有12
MB二级缓存。英特尔这一次并未选择成倍增加二级缓存,而是增加了50%,这可能是因为将加入某些新功能,或者是基于成本/效能比的考虑以及降低多内核产品的生产难度,但从二级缓存的容量上看来,英特尔将不会在这些产品中集成内存控制器。

45纳米CPU
CHIP结论
烽烟再起
目前英特尔的几座45纳米工艺新厂正在紧张建设以确保产能,毫无疑问,采用Core微架构的65纳米和45纳米产品将打响一场非常漂亮的反击战,而AMD的65纳米工艺最早也要到2006年年底才能投产,而且产能是否能满足需要还是一个疑问,未来的两年内,将是AMD生死攸关的岁月。从IBM发布的研究信息来看,它的45纳米,以及后续的29.9纳米工艺研究并没有遇到困难,因此在制造工艺方面,AMD虽然落后于英特尔,但1年左右的差距并非是致命的;但在新架构的设计方面,
K9/K10如果不尽快出现的话,已经老迈的K8架构将很难抵御45纳米工艺的Core微架构产品的攻势,AMD可能将再次被迫放弃主流市场。但我们仍然希望竞争格局的延续,这样消费者才能更快地用上更好、更廉价的产品。
TOP |
